


La PS3 può giocare a FIFA 21?
FIFA 21 è compatibile con la console di gioco PS3? FIFA 21, l’ultimo capitolo della famosa serie di videogiochi di calcio sviluppata da EA Sports, è …
Leggi l'articolo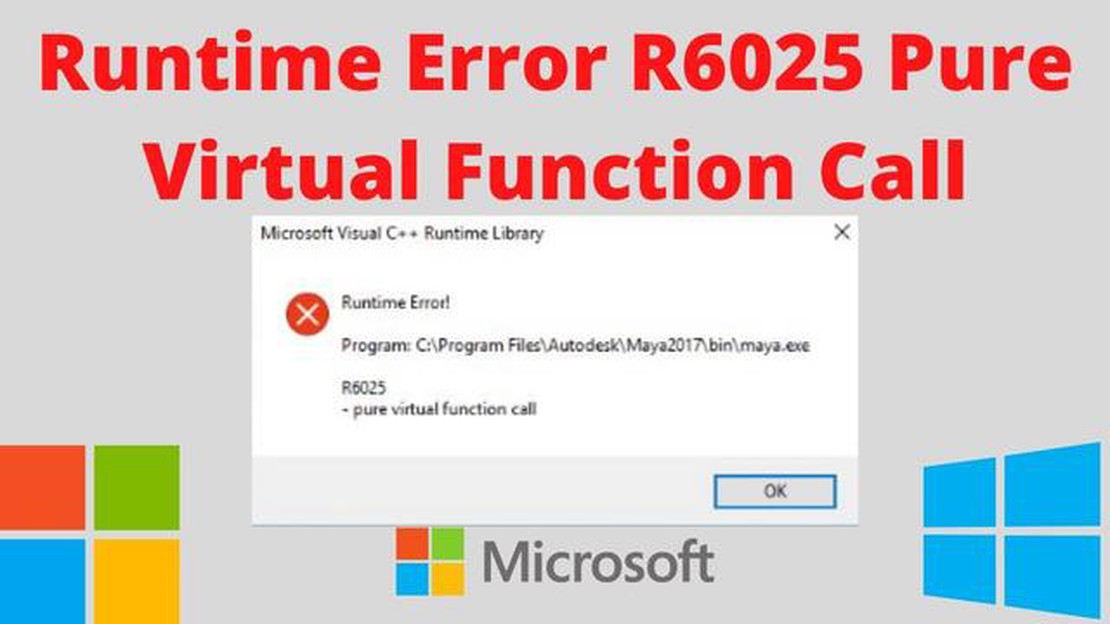
Comprendere e utilizzare efficacemente le chiamate a funzioni pure è fondamentale per qualsiasi programmatore, ma può essere fonte di confusione e frustrazione quando si verificano degli errori. Le funzioni pure sono funzioni che restituiscono lo stesso output per lo stesso input, senza causare effetti collaterali. Quando queste funzioni vengono chiamate in modo errato, possono portare a risultati inaspettati e a bug nel codice.
Un errore comune quando si chiamano le funzioni pure è quello di non fornire gli argomenti corretti. Le funzioni pure si basano su input specifici per produrre l’output desiderato. Se si passano gli argomenti sbagliati alla funzione, questa può restituire risultati inattesi o addirittura lanciare un errore. È importante esaminare attentamente la documentazione della funzione e assicurarsi che gli argomenti corretti siano passati nell’ordine corretto.
Un altro errore consiste nel non assegnare il valore di ritorno di una funzione pura a una variabile. Poiché le funzioni pure non modificano alcuno stato esterno, il loro valore di ritorno deve essere catturato e utilizzato per avere un impatto sul programma. Se si trascura di assegnare il valore di ritorno, la chiamata di funzione non ha alcun effetto, con conseguenti errori e spreco di risorse computazionali.
Uno scenario comune in cui può verificarsi l’errore di chiamata di funzione pura è l’utilizzo di paradigmi di programmazione funzionale. La programmazione funzionale si basa molto sulle funzioni pure e capire come chiamarle correttamente è essenziale. Inoltre, molte librerie e framework in vari linguaggi di programmazione utilizzano funzioni pure, quindi conoscere le convenzioni di chiamata corrette è importante per utilizzare efficacemente questi strumenti.
Per correggere ed evitare errori di chiamata di funzioni pure, è importante leggere attentamente la documentazione della funzione e capire il comportamento previsto. Prestare molta attenzione agli argomenti richiesti, al loro ordine e al valore di ritorno previsto. Assegnare sempre il valore di ritorno di una funzione pura a una variabile, assicurandosi che venga utilizzato nella logica del programma. Adottando queste precauzioni, è possibile evitare gli errori più comuni e garantire che le chiamate a funzioni pure siano accurate e prive di errori.
Quando si lavora con le funzioni pure nel gioco, è importante comprendere gli errori comuni che possono verificarsi quando si chiamano queste funzioni. Le funzioni pure sono funzioni che non hanno effetti collaterali e restituiscono sempre lo stesso risultato con lo stesso input.
Un errore comune è quello di non passare gli argomenti corretti alla funzione. Le funzioni pure si basano molto sulla presenza di input coerenti per garantire output coerenti. Se si passano gli argomenti sbagliati a una funzione pura, l’output può essere errato o inaspettato. È importante esaminare attentamente la documentazione della funzione pura e assicurarsi che vengano utilizzati gli argomenti corretti.
Un altro errore consiste nel modificare lo stato di una variabile all’interno di una funzione pura. Le funzioni pure non dovrebbero modificare alcuna variabile al di fuori del loro ambito. La modifica dello stato di una variabile può portare a risultati imprevedibili e rendere la funzione impura. È invece importante creare variabili locali all’interno della funzione pura e manipolarle.
Inoltre, anche chiamare funzioni impure all’interno di una funzione pura è un errore comune. Le funzioni impure sono funzioni che hanno effetti collaterali, come la modifica di variabili globali o la creazione di richieste di rete. Chiamare una funzione impura all’interno di una funzione pura può introdurre effetti collaterali inaspettati e rendere impura anche la funzione pura. È importante chiamare solo altre funzioni pure all’interno di una funzione pura per garantire la coerenza.
In sintesi, quando si lavora con le funzioni pure nel gioco, è fondamentale assicurarsi che vengano passati gli argomenti corretti, evitare di modificare lo stato delle variabili e chiamare solo altre funzioni pure. Evitando questi errori comuni, gli sviluppatori possono sfruttare la potenza delle funzioni pure per creare esperienze di gioco più prevedibili e affidabili.
Uno degli errori più comuni quando si tratta di chiamate a funzioni pure è ignorare l’immutabilità degli input. In una funzione pura, gli input sono considerati immutabili, cioè non possono essere modificati all’interno della funzione. Questo garantisce che la funzione restituisca sempre lo stesso output per lo stesso input.
Tuttavia, a volte gli sviluppatori modificano involontariamente i valori di input all’interno della funzione. Questo può portare a risultati inaspettati e rendere la funzione impura. Ad esempio, se una funzione deve calcolare la media di un elenco di numeri, ma modifica l’elenco rimuovendo un valore, non è più una funzione pura. La volta successiva che la funzione viene richiamata con lo stesso elenco, potrebbe restituire una media diversa.
Per evitare questo errore, è importante trattare gli input in sola lettura all’interno delle funzioni pure. Invece di modificare direttamente gli input, bisogna creare nuove variabili o strutture dati per eseguire i calcoli o le trasformazioni necessarie. In questo modo, i valori di input originali rimangono invariati.
Inoltre, è buona norma utilizzare l’immutabilità delle strutture dati passate come input alle funzioni pure. I dati immutabili garantiscono che la funzione non possa modificare accidentalmente i dati, rendendo più facile il ragionamento e il test. I dati immutabili possono essere ottenuti utilizzando librerie o tecniche di programmazione che impongono l’immutabilità.
In sintesi, ignorare l’immutabilità degli input è un errore comune quando si lavora con le chiamate a funzioni pure. Per evitare questo errore, bisogna trattare gli input come di sola lettura e utilizzare l’immutabilità nelle strutture dati passate alle funzioni pure. Seguendo queste pratiche, si può garantire che le funzioni pure si comportino in modo prevedibile e coerente.
Un errore comune nell’uso delle funzioni pure è quello di trascurare i valori di ritorno. Quando si chiama una funzione pura, è importante prestare attenzione al valore che restituisce, perché potrebbe essere necessario per ulteriori calcoli o per visualizzare informazioni all’utente.
Ad esempio, se una funzione pura calcola il risultato di un’operazione matematica, ma il valore di ritorno non viene assegnato a una variabile o utilizzato in alcun modo, il calcolo andrebbe sostanzialmente sprecato. Questo può portare a errori e inefficienze nel codice.
Per evitare questo errore, è importante assegnare sempre il valore di ritorno di una funzione pura a una variabile o utilizzarlo in modo significativo. In questo modo, il risultato del calcolo può essere utilizzato in modo efficace.
Inoltre, trascurare i valori di ritorno può causare comportamenti imprevisti o errori quando si concatenano le chiamate a funzioni pure. Se il valore di ritorno di una funzione pura non viene passato come argomento alla chiamata di funzione successiva, quest’ultima potrebbe non ricevere l’input previsto e produrre risultati errati.
Per evitare che ciò accada, è fondamentale considerare attentamente i valori di ritorno delle funzioni pure e assicurarsi che vengano utilizzati correttamente nei calcoli o nelle chiamate di funzione successive. Questo può aiutare a mantenere l’integrità e la correttezza del codice.
Leggi anche: 5 modi per aumentare il vostro limite Afterpay
Nella programmazione funzionale, le funzioni pure sono un concetto chiave. Sono funzioni che producono sempre lo stesso output con lo stesso input e non hanno effetti collaterali. Tuttavia, in alcuni casi può essere necessario utilizzare funzioni impure all’interno di funzioni pure.
Una funzione impura è una funzione che modifica lo stato o ha effetti collaterali. Può includere azioni come la stampa sulla console, la lettura di un file o l’esecuzione di richieste HTTP. Sebbene le funzioni impure siano generalmente sconsigliate nei paradigmi di programmazione pura, ci sono situazioni in cui possono essere necessarie.
Uno scenario comune in cui si utilizzano funzioni impure all’interno di funzioni pure è quando si ha a che fare con dipendenze esterne. Ad esempio, se una funzione pura richiede dei dati da un database, potrebbe dover chiamare una funzione impura per recuperare tali dati. In questo caso, la funzione impura può essere incapsulata e chiamata all’interno di una funzione pura per garantire che la funzione complessiva rimanga pura.
Per utilizzare una funzione impura all’interno di una funzione pura, è importante che la chiamata alla funzione impura sia isolata e contenuta. Questo aiuta a mantenere la purezza della funzione complessiva e rende più facile ragionare sul comportamento del programma. È inoltre buona norma documentare chiaramente ogni chiamata di funzione impura all’interno del codice, in modo da rendere evidente l’esistenza dell’impurità.
Leggi anche: Rivelato l'oggetto più venduto di Stardew Valley!
Quando si utilizzano funzioni impure all’interno di funzioni pure, è importante gestire ogni potenziale errore o effetto collaterale che potrebbe verificarsi. Questo può essere fatto utilizzando meccanismi di gestione degli errori come i blocchi try-catch o utilizzando costrutti funzionali come le monadi Maybe o Either per gestire eventuali fallimenti. Una corretta gestione degli errori aiuta a mantenere l’integrità della funzione pura e garantisce un programma più robusto.
Un errore comune che gli sviluppatori commettono quando scrivono il codice è quello di trascurare una corretta gestione degli errori. La gestione degli errori è una parte essenziale della programmazione, in quanto consente di gestire situazioni impreviste e di fornire un feedback appropriato agli utenti.
Quando il codice viene scritto senza gestire gli errori, può portare a un comportamento imprevedibile e potenzialmente all’arresto dell’applicazione. Ad esempio, se un file non viene trovato quando si cerca di aprirlo, il programma può lanciare un errore e terminare bruscamente. Questo non solo frustra gli utenti, ma rende anche difficile diagnosticare e risolvere il problema.
Un’altra conseguenza della mancata gestione degli errori è che l’applicazione può essere vulnerabile alle minacce alla sicurezza. Ad esempio, se un utente inserisce un input non valido in un modulo e l’applicazione non lo gestisce correttamente, potrebbe portare a violazioni dei dati o ad altre attività dannose.
Per evitare questi problemi, è importante implementare la gestione degli errori nel codice. Ciò può essere fatto utilizzando blocchi try-catch per catturare e gestire le eccezioni, convalidando l’input dell’utente prima di elaborarlo e fornendo messaggi di errore significativi agli utenti.
Oltre a gestire gli errori con garbo, è anche importante registrare gli errori e le eccezioni che si verificano nell’applicazione. Ciò consente di individuare e risolvere i bug in modo più efficace, potendo vedere quando e dove si verificano gli errori. La registrazione può essere effettuata utilizzando librerie o funzioni integrate, a seconda del linguaggio di programmazione utilizzato.
In generale, trascurare la gestione degli errori è un errore comune che può avere gravi conseguenze per l’applicazione. Implementando le corrette tecniche di gestione degli errori, è possibile migliorare l’affidabilità, la sicurezza e l’esperienza utente del codice.
Un errore comune quando si ha a che fare con le chiamate a funzioni pure è quello di non comprendere il concetto di trasparenza referenziale. La trasparenza referenziale è una proprietà delle funzioni pure che afferma che una funzione produrrà sempre lo stesso output per lo stesso input.
Quando gli sviluppatori non comprendono questo concetto, possono inavvertitamente introdurre effetti collaterali o dipendere da uno stato mutabile nelle loro chiamate a funzioni pure. Questo può portare a comportamenti inaspettati e rendere difficile il ragionamento sul codice.
Ad esempio, immaginiamo una funzione pura che calcola il quadrato di un dato numero. Se chiamiamo questa funzione con un input di 4, ci aspettiamo che l’output sia 16. Tuttavia, se la funzione dipende da una funzione di input, il risultato sarà 16. Tuttavia, se la funzione dipende da una variabile globale che può essere modificata in un altro punto del codice, l’output della funzione può cambiare a seconda dello stato della variabile. Questo viola la trasparenza referenziale.
Per evitare questo errore, è importante analizzare attentamente le dipendenze e gli effetti collaterali di una funzione pura prima di chiamarla. Se una funzione si basa su uno stato mutabile o ha effetti collaterali, deve essere rifattorizzata per rimuovere queste dipendenze e garantire la trasparenza referenziale.
Un modo per ottenere questo risultato è utilizzare strutture di dati immutabili ed evitare lo stato globale. Assicurando che tutti gli input di una funzione pura siano immutabili e che la funzione non modifichi alcuno stato al di fuori del proprio ambito, si può garantire la trasparenza referenziale.
Un altro approccio consiste nell’utilizzare tecniche di programmazione funzionale, come le funzioni di ordine superiore e la composizione funzionale pura. Scomponendo compiti complessi in funzioni più piccole e pure e concatenandole tra loro mediante la composizione, si può creare codice più facile da ragionare e meno soggetto a errori.
In conclusione, la mancata comprensione della trasparenza referenziale può portare a errori e comportamenti inaspettati nelle chiamate a funzioni pure. È importante analizzare attentamente le dipendenze e gli effetti collaterali di una funzione e rifattorizzarla, se necessario, per garantire la trasparenza referenziale. Utilizzando strutture di dati immutabili e tecniche di programmazione funzionale, possiamo scrivere codice più affidabile e manutenibile.
L’errore di chiamata di funzione pura è un errore comune che si verifica quando una funzione pura viene chiamata con argomenti impuri o non costanti.
La comprensione dell’errore di chiamata di funzione pura è importante perché può portare a comportamenti inaspettati e a bug nel codice. Comprendendo gli errori più comuni e come risolverli, è possibile scrivere codice più affidabile e manutenibile.
È possibile risolvere l’errore di chiamata di funzione pura assicurandosi che gli argomenti passati a una funzione pura siano puri e non abbiano effetti collaterali. Se necessario, si può rifattorizzare il codice per separare le parti impure da quelle pure o utilizzare tecniche come la memoizzazione per memorizzare i risultati delle chiamate a funzioni impure.
Alcuni errori comuni che possono causare l’errore di chiamata di funzione pura includono la chiamata di una funzione impura all’interno di una funzione pura, il passaggio di argomenti impuri o non costanti a una funzione pura o l’affidamento a uno stato mutabile all’interno di una funzione pura.
Sì, esistono strumenti e liner come ESLint con il plugin eslint-plugin-pureness che possono aiutare a rilevare e prevenire l’errore di chiamata di funzione pura. Questi strumenti possono analizzare il codice ed evidenziare qualsiasi potenziale violazione della purezza.
FIFA 21 è compatibile con la console di gioco PS3? FIFA 21, l’ultimo capitolo della famosa serie di videogiochi di calcio sviluppata da EA Sports, è …
Leggi l'articolo
“Qual è il tipo di carne meno salutare per il consumo e i suoi effetti negativi sulla salute?”. **Il consumo di carne è un argomento controverso che …
Leggi l'articolo
FIFA 20 avrà il viaggio? Il videogioco di calcio di punta di Electronic Arts, FIFA, affascina i fan di tutto il mondo da decenni. Ogni anno, l’azienda …
Leggi l'articolo
Si può costruire un fossato a Valheim? Valheim, il popolare gioco di sopravvivenza a mondo aperto, ha affascinato i giocatori con il suo coinvolgente …
Leggi l'articolo
Che dimensioni dovrebbe avere la scrivania per i giochi? Quando si tratta di giocare, avere la giusta configurazione è fondamentale per un’esperienza …
Leggi l'articolo
Quali sono le fasi della contrazione muscolare? La contrazione muscolare è un processo fisiologico complesso che permette al nostro corpo di muoversi …
Leggi l'articolo


