


Jakie urządzenie oferuje najlepsze wrażenia z gry w Roblox?
Na jakim urządzeniu najlepiej grać w Roblox? W świecie gier Roblox stał się fenomenem, urzekając miliony graczy na całym świecie swoją kreatywną …
Przeczytaj artykuł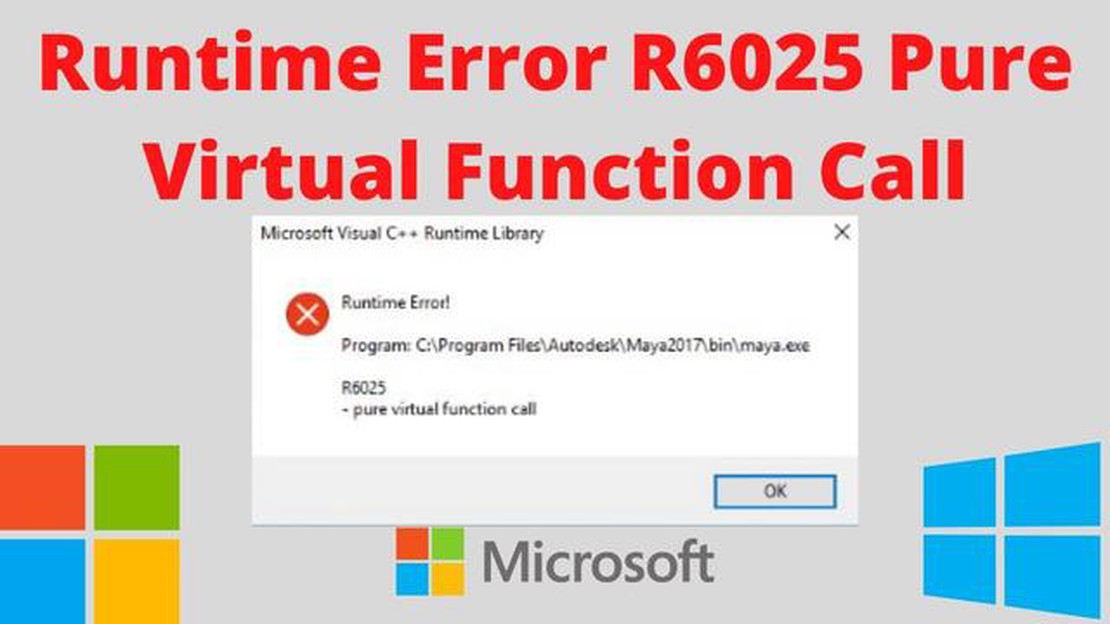
Zrozumienie i efektywne wykorzystanie czystych wywołań funkcji jest kluczowe dla każdego programisty, ale może być źródłem zamieszania i frustracji, gdy wystąpią błędy. Czyste funkcje to funkcje, które zwracają te same dane wyjściowe dla tych samych danych wejściowych, nie powodując żadnych skutków ubocznych. Nieprawidłowe wywołanie tych funkcji może prowadzić do nieoczekiwanych rezultatów i błędów w kodzie.
Jednym z częstych błędów podczas wywoływania czystych funkcji jest niedostarczenie prawidłowych argumentów. Czyste funkcje polegają na określonych danych wejściowych w celu uzyskania pożądanego wyniku. Jeśli do funkcji zostaną przekazane niewłaściwe argumenty, może ona zwrócić nieoczekiwane wyniki lub nawet zgłosić błąd. Ważne jest, aby dokładnie przejrzeć dokumentację funkcji i upewnić się, że prawidłowe argumenty są przekazywane we właściwej kolejności.
Kolejnym błędem jest brak przypisania wartości zwracanej czystej funkcji do zmiennej. Ponieważ czyste funkcje nie modyfikują żadnego stanu zewnętrznego, ich wartość zwracana musi zostać przechwycona i wykorzystana, aby miała jakikolwiek wpływ na program. Zaniedbanie przypisania wartości zwracanej może spowodować, że wywołanie funkcji nie przyniesie żadnego efektu, prowadząc do subtelnych błędów i marnowania zasobów obliczeniowych.
Jednym z typowych scenariuszy, w których może wystąpić błąd czystego wywołania funkcji, jest korzystanie z paradygmatów programowania funkcjonalnego. Programowanie funkcjonalne opiera się w dużej mierze na czystych funkcjach, a zrozumienie, jak prawidłowo je wywoływać, jest niezbędne. Ponadto wiele bibliotek i frameworków w różnych językach programowania wykorzystuje czyste funkcje, więc znajomość prawidłowych konwencji wywoływania jest ważna dla efektywnego wykorzystania tych narzędzi.
Aby naprawić i uniknąć błędów wywołania czystej funkcji, ważne jest, aby uważnie przeczytać dokumentację funkcji i zrozumieć oczekiwane zachowanie. Zwróć szczególną uwagę na wymagane argumenty, ich kolejność i oczekiwaną wartość zwracaną. Zawsze przypisuj wartość zwracaną czystej funkcji do zmiennej, upewniając się, że jest ona wykorzystywana w logice programu. Podejmując te środki ostrożności, można uniknąć typowych błędów i upewnić się, że wywołania czystych funkcji są dokładne i wolne od błędów.
Podczas pracy z czystymi funkcjami w grach ważne jest, aby zrozumieć typowe błędy, które mogą wystąpić podczas wywoływania tych funkcji. Czyste funkcje to funkcje, które nie mają efektów ubocznych i zawsze zwracają te same dane wyjściowe przy tych samych danych wejściowych.
Jednym z najczęstszych błędów jest nieprzekazywanie prawidłowych argumentów do funkcji. Czyste funkcje polegają w dużej mierze na spójnych danych wejściowych, aby zapewnić spójne dane wyjściowe. Jeśli do czystej funkcji zostaną przekazane niewłaściwe argumenty, dane wyjściowe mogą być nieprawidłowe lub nieoczekiwane. Ważne jest, aby dokładnie przejrzeć dokumentację czystej funkcji i upewnić się, że używane są prawidłowe argumenty.
Innym błędem jest modyfikowanie stanu zmiennej w czystej funkcji. Funkcje czyste nie powinny modyfikować żadnych zmiennych poza swoim zakresem. Modyfikowanie stanu zmiennej może prowadzić do nieprzewidywalnych wyników i uczynić funkcję nieczystą. Zamiast tego ważne jest, aby tworzyć zmienne lokalne w ramach czystej funkcji i manipulować nimi.
Ponadto częstym błędem jest wywoływanie nieczystych funkcji w ramach czystej funkcji. Nieczyste funkcje to funkcje, które mają efekty uboczne, takie jak modyfikowanie zmiennych globalnych lub wykonywanie żądań sieciowych. Wywołanie nieczystej funkcji wewnątrz czystej funkcji może wprowadzić nieoczekiwane efekty uboczne i sprawić, że czysta funkcja również stanie się nieczysta. Ważne jest, aby wywoływać inne czyste funkcje tylko w ramach czystej funkcji, aby zapewnić spójność.
Podsumowując, podczas pracy z czystymi funkcjami w grach ważne jest, aby upewnić się, że przekazywane są prawidłowe argumenty, unikać modyfikowania stanu zmiennych i wywoływać tylko inne czyste funkcje. Unikając tych typowych błędów, programiści mogą wykorzystać moc czystych funkcji do tworzenia bardziej przewidywalnych i niezawodnych doświadczeń w grach.
Jednym z najczęstszych błędów podczas wywoływania czystych funkcji jest ignorowanie niezmienności danych wejściowych. W czystej funkcji dane wejściowe są uważane za niezmienne, co oznacza, że nie można ich zmienić w ramach funkcji. Gwarantuje to, że funkcja zawsze zwróci ten sam wynik dla tego samego wejścia.
Czasami jednak programiści nieumyślnie modyfikują wartości wejściowe w ramach funkcji. Może to prowadzić do nieoczekiwanych rezultatów i uczynić funkcję nieczystą. Na przykład, jeśli funkcja ma obliczyć średnią z listy liczb, ale modyfikuje listę poprzez usunięcie wartości, nie jest już czystą funkcją. Następnym razem, gdy funkcja zostanie wywołana z tą samą listą, może zwrócić inną średnią.
Aby zapobiec temu błędowi, ważne jest, aby traktować dane wejściowe jako tylko do odczytu w czystych funkcjach. Zamiast bezpośrednio modyfikować dane wejściowe, należy utworzyć nowe zmienne lub struktury danych w celu wykonania niezbędnych obliczeń lub przekształceń. W ten sposób oryginalne wartości wejściowe pozostaną niezmienione.
Ponadto dobrą praktyką jest stosowanie niezmienności w strukturach danych przekazywanych jako dane wejściowe do czystych funkcji. Niezmienne dane zapewniają, że funkcja nie może przypadkowo zmodyfikować danych, co ułatwia rozumowanie i testowanie. Niezmienne dane można osiągnąć za pomocą bibliotek lub technik programowania, które wymuszają niezmienność.
Podsumowując, ignorowanie niezmienności danych wejściowych jest częstym błędem podczas pracy z czystymi wywołaniami funkcji. Aby uniknąć tego błędu, należy traktować dane wejściowe jako tylko do odczytu i używać niezmienności w strukturach danych przekazywanych do czystych funkcji. Postępując zgodnie z tymi praktykami, można zapewnić, że czyste funkcje zachowują się przewidywalnie i konsekwentnie.
Jednym z częstych błędów podczas korzystania z czystych funkcji jest pomijanie wartości zwracanych. Podczas wywoływania czystej funkcji ważne jest, aby zwracać uwagę na zwracaną przez nią wartość, ponieważ może ona być potrzebna do dalszych obliczeń lub do wyświetlania informacji użytkownikowi.
Na przykład, jeśli czysta funkcja obliczy wynik operacji matematycznej, ale wartość zwracana nie zostanie przypisana do zmiennej lub wykorzystana w jakikolwiek sposób, obliczenia zostaną zasadniczo zmarnowane. Może to prowadzić do błędów i nieefektywności kodu.
Aby uniknąć tego błędu, ważne jest, aby zawsze przypisywać wartość zwracaną czystej funkcji do zmiennej lub używać jej w znaczący sposób. W ten sposób można efektywnie wykorzystać wynik obliczeń.
Ponadto pomijanie wartości zwracanych może również skutkować nieoczekiwanym zachowaniem lub błędami podczas łączenia czystych wywołań funkcji. Jeśli wartość zwracana jednej czystej funkcji nie zostanie przekazana jako argument do następnego wywołania funkcji, kolejna funkcja może nie otrzymać oczekiwanych danych wejściowych i może wygenerować nieprawidłowe wyniki.
Aby temu zapobiec, ważne jest, aby dokładnie rozważyć wartości zwracane przez czyste funkcje i upewnić się, że są one poprawnie używane w kolejnych obliczeniach lub wywołaniach funkcji. Może to pomóc w utrzymaniu integralności i poprawności kodu.
Czytaj także: Proste kroki do uruchomienia HBO Go na telewizorze Smart TV
W programowaniu funkcjonalnym czyste funkcje są kluczową koncepcją. Są to funkcje, które zawsze generują te same dane wyjściowe przy tych samych danych wejściowych i nie mają efektów ubocznych. Jednak w niektórych przypadkach może być konieczne użycie nieczystych funkcji w czystych funkcjach.
Funkcja nieczysta to funkcja, która modyfikuje stan lub ma efekty uboczne. Może to obejmować działania takie jak drukowanie do konsoli, odczytywanie z pliku lub wykonywanie żądań HTTP. Chociaż nieczyste funkcje są generalnie odradzane w czystych paradygmatach programowania, istnieją sytuacje, w których mogą być konieczne.
Jednym z typowych scenariuszy, w których nieczyste funkcje są używane w czystych funkcjach, jest radzenie sobie z zewnętrznymi zależnościami. Na przykład, jeśli czysta funkcja wymaga danych z bazy danych, może być konieczne wywołanie nieczystej funkcji w celu pobrania tych danych. W takim przypadku funkcja nieczysta może być hermetyzowana i wywoływana w ramach funkcji czystej, aby zapewnić, że ogólna funkcja pozostanie czysta.
Aby użyć nieczystej funkcji w czystej funkcji, ważne jest, aby nieczyste wywołanie funkcji było odizolowane i zamknięte. Pomaga to zachować czystość całej funkcji i ułatwia wnioskowanie o zachowaniu programu. Dobrą praktyką jest również wyraźne dokumentowanie wszelkich nieczystych wywołań funkcji w kodzie, aby było jasne, gdzie występuje nieczystość.
Czytaj także: Porównanie prędkości: Mona vs Ayaka
Podczas korzystania z nieczystych funkcji w ramach czystych funkcji ważne jest, aby obsługiwać wszelkie potencjalne błędy lub efekty uboczne, które mogą się pojawić. Można to zrobić za pomocą mechanizmów obsługi błędów, takich jak bloki try-catch lub przy użyciu konstrukcji funkcjonalnych, takich jak monady Maybe lub Either, aby poradzić sobie z możliwymi awariami. Właściwa obsługa błędów pomaga zachować integralność czystej funkcji i zapewnia bardziej niezawodny program.
Jednym z częstych błędów popełnianych przez programistów podczas pisania kodu jest zaniedbywanie właściwej obsługi błędów. Obsługa błędów jest istotną częścią programowania, ponieważ pozwala radzić sobie z nieoczekiwanymi sytuacjami i zapewniać użytkownikom odpowiednie informacje zwrotne.
Gdy kod jest napisany bez obsługi błędów, może to prowadzić do nieprzewidywalnego zachowania i potencjalnie spowodować awarię aplikacji. Na przykład, jeśli plik nie zostanie znaleziony podczas próby jego otwarcia, program może zgłosić błąd i nagle się zakończyć. Nie tylko frustruje to użytkowników, ale także utrudnia zdiagnozowanie i naprawienie problemu.
Inną konsekwencją zaniedbania obsługi błędów jest narażenie aplikacji na zagrożenia bezpieczeństwa. Na przykład, jeśli użytkownik wprowadzi nieprawidłowe dane do formularza, a aplikacja nie obsłuży ich prawidłowo, może to prowadzić do naruszenia danych lub innych złośliwych działań.
Aby uniknąć tych problemów, ważne jest zaimplementowanie obsługi błędów w kodzie. Można to zrobić za pomocą bloków try-catch do wychwytywania i obsługi wyjątków, walidacji danych wprowadzanych przez użytkownika przed ich przetworzeniem oraz dostarczania użytkownikom znaczących komunikatów o błędach.
Oprócz sprawnej obsługi błędów, ważne jest również rejestrowanie błędów i wyjątków występujących w aplikacji. Pozwala to na skuteczniejsze śledzenie i naprawianie błędów, ponieważ można zobaczyć, kiedy i gdzie występują błędy. Rejestrowanie może odbywać się za pomocą bibliotek lub wbudowanych funkcji, w zależności od używanego języka programowania.
Ogólnie rzecz biorąc, zaniedbywanie obsługi błędów jest częstym błędem, który może mieć poważne konsekwencje dla aplikacji. Wdrażając odpowiednie techniki obsługi błędów, można poprawić niezawodność, bezpieczeństwo i komfort użytkowania kodu.
Jednym z najczęstszych błędów związanych z czystymi wywołaniami funkcji jest niezrozumienie koncepcji przezroczystości referencyjnej. Przezroczystość referencyjna jest właściwością czystych funkcji, która stwierdza, że funkcja zawsze będzie generować te same dane wyjściowe dla tych samych danych wejściowych.
Gdy programiści nie rozumieją tej koncepcji, mogą nieumyślnie wprowadzić efekty uboczne lub polegać na zmiennym stanie w swoich czystych wywołaniach funkcji. Może to prowadzić do nieoczekiwanego zachowania i utrudniać rozumowanie kodu.
Dla przykładu, wyobraźmy sobie czystą funkcję, która oblicza kwadrat danej liczby. Jeśli wywołamy tę funkcję z wejściem 4, spodziewalibyśmy się, że wynikiem będzie 16. Jeśli jednak funkcja zależy od zmiennej globalnej, która może być modyfikowana w innym miejscu kodu, wynik funkcji może się zmienić w zależności od stanu zmiennej. Narusza to przezroczystość referencyjną.
Aby uniknąć tego błędu, ważne jest, aby dokładnie przeanalizować zależności i efekty uboczne czystej funkcji przed jej wywołaniem. Jeśli funkcja opiera się na zmiennym stanie lub ma efekty uboczne, powinna zostać refaktoryzowana w celu usunięcia tych zależności i zapewnienia przejrzystości referencyjnej.
Jednym ze sposobów na osiągnięcie tego jest użycie niezmiennych struktur danych i unikanie stanu globalnego. Zapewniając, że wszystkie wejścia do czystej funkcji są niezmienne i że funkcja nie modyfikuje żadnego stanu poza swoim własnym zakresem, możemy zagwarantować przejrzystość referencyjną.
Innym podejściem jest wykorzystanie technik programowania funkcjonalnego, takich jak funkcje wyższego rzędu i czysta kompozycja funkcjonalna. Rozbijając złożone zadania na mniejsze, czyste funkcje i łącząc je ze sobą za pomocą kompozycji, możemy tworzyć kod, który jest łatwiejszy do zrozumienia i mniej podatny na błędy.
Podsumowując, niezrozumienie przezroczystości referencyjnej może prowadzić do błędów i nieoczekiwanego zachowania w czystych wywołaniach funkcji. Ważne jest, aby dokładnie przeanalizować zależności i efekty uboczne funkcji i w razie potrzeby zrefaktoryzować ją, aby zapewnić przejrzystość referencyjną. Korzystając z niezmiennych struktur danych i technik programowania funkcjonalnego, możemy pisać kod, który jest bardziej niezawodny i łatwy w utrzymaniu.
Błąd wywołania czystej funkcji jest powszechnym błędem, który występuje, gdy czysta funkcja jest wywoływana z nieczystymi lub niestałymi argumentami.
Zrozumienie błędu wywołania czystej funkcji jest ważne, ponieważ może prowadzić do nieoczekiwanego zachowania i błędów w kodzie. Rozumiejąc typowe błędy i sposoby ich naprawy, można pisać bardziej niezawodny i łatwy w utrzymaniu kod.
Błąd wywołania czystej funkcji można naprawić, upewniając się, że argumenty przekazywane do czystej funkcji są czyste i nie mają żadnych skutków ubocznych. W razie potrzeby można refaktoryzować kod, aby oddzielić nieczyste i czyste części, lub użyć technik takich jak memoizacja do buforowania wyników nieczystych wywołań funkcji.
Niektóre typowe błędy, które mogą powodować błąd wywołania czystej funkcji, obejmują wywoływanie nieczystej funkcji wewnątrz czystej funkcji, przekazywanie nieczystych lub niestałych argumentów do czystej funkcji lub poleganie na zmiennym stanie w czystej funkcji.
Tak, istnieją narzędzia i lintery, takie jak ESLint z wtyczką eslint-plugin-pureness, które mogą pomóc wykryć i zapobiec błędowi wywołania czystej funkcji. Narzędzia te mogą analizować kod i podkreślać wszelkie potencjalne naruszenia czystości.
Na jakim urządzeniu najlepiej grać w Roblox? W świecie gier Roblox stał się fenomenem, urzekając miliony graczy na całym świecie swoją kreatywną …
Przeczytaj artykuł
Jak działa pre-patch TBC? Premiera pre-patcha The Burning Crusade (TBC) wywołała falę ekscytacji wśród graczy World of Warcraft. Ta wyczekiwana …
Przeczytaj artykuł
Z kim powinienem romansować w Dragon’s Dogma? Dragon’s Dogma, popularna fabularna gra akcji opracowana i wydana przez Capcom, oferuje graczom …
Przeczytaj artykuł
Jak sprawdzić, która jest godzina w Dragon’s Dogma? Jeśli jesteś fanem popularnej fabularnej gry akcji Dragon’s Dogma, być może zastanawiałeś się, jak …
Przeczytaj artykuł
O której jest banner Ayaki? Bardzo oczekiwana postać Ayaka zadebiutuje w popularnej grze Genshin Impact. Ayaka jest 5-gwiazdkowym użytkownikiem miecza …
Przeczytaj artykuł
Kim są cztery wiatry, na które oddziałuje Genshin? Genshin Impact, popularna fabularna gra akcji stworzona przez miHoYo, zabiera graczy w podróż przez …
Przeczytaj artykuł



